No atual cenário de arquitetura de software, existem pelo menos 2 paradigmas comuns para resolver a comunicação entre diferentes serviços: síncrona e assíncrona. A primeira forma de comunicação pode ser implementada utilizando o modelo mais comum de chamadas entre serviços que é a troca de requisições HTTP. A segunda, por sua vez, é mais frequentemente implementada utilizando brokers de mensageria.
Ambos padrões de comunicação apresentam seus prós e contras – e é sobre esses tradeoffs que a gente vai falar um pouquinho aqui.
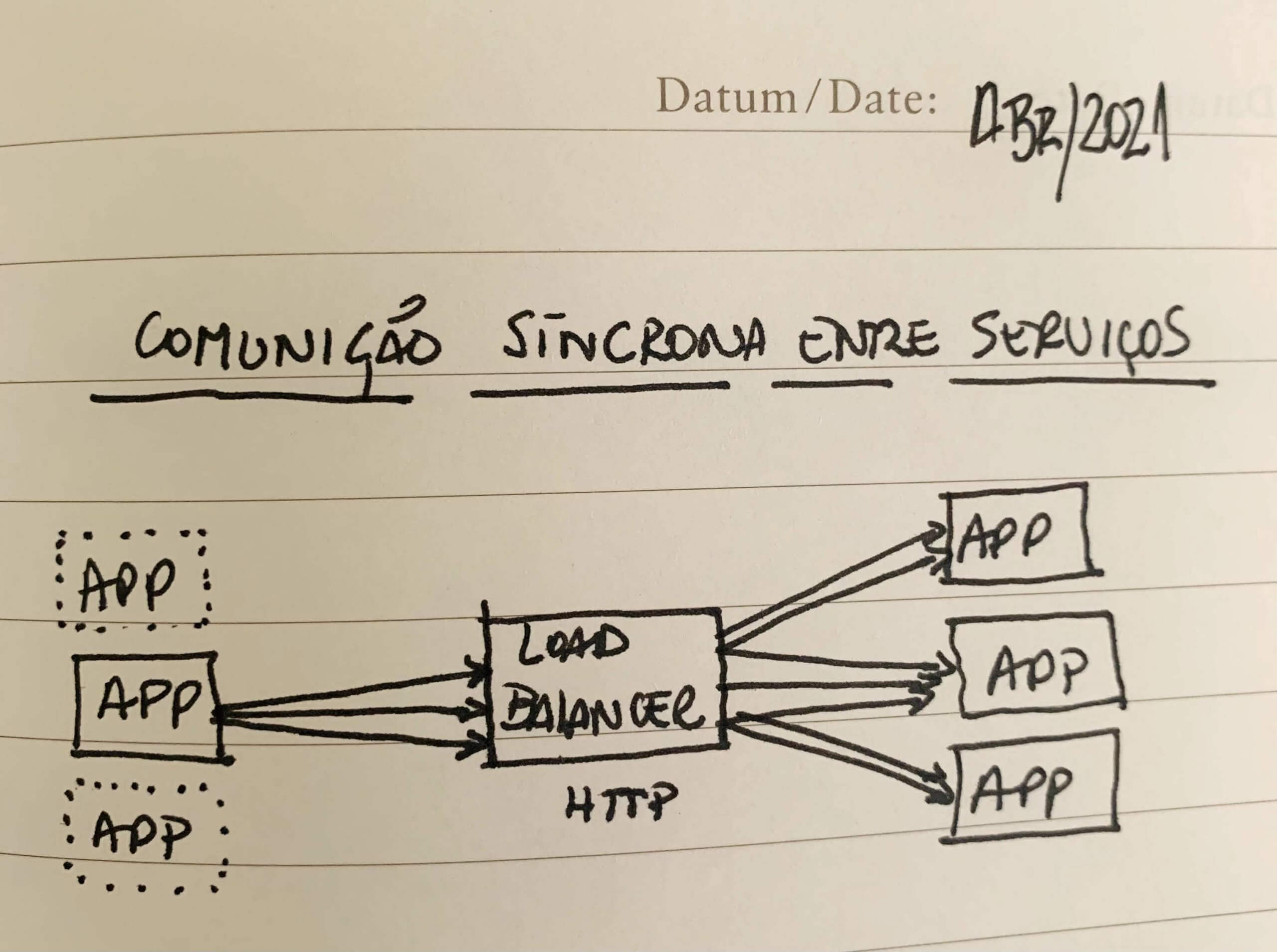
 Comunicação síncrona: modelo HTTP convencional
Comunicação síncrona: modelo HTTP convencional
O protocolo HTTP está entre nós há décadas e, portanto, no mundo do desenvolvimento de software, ele já é amplamente conhecido e é basicamente a peça fundamental para o acesso a todo tipo de conteúdo na internet.
 Entre os prós que o modelo de comunicação entre serviços síncrono usando HTTP pode oferecer, podemos destacar:
Entre os prós que o modelo de comunicação entre serviços síncrono usando HTTP pode oferecer, podemos destacar:
- Facilidade de implementação;
- Atende bem grande parte dos cenários de comunicação entre serviços que não demandam uma alta taxa de concorrência;
- Possui um universo vasto de documentação, bibliotecas e exemplos para se inspirar e implementar.
Por outro lado, como pontos de atenção, vale citar:
- De maneira geral, não é um modelo que escala para altos níveis de concorrência ( > 1K TPS, por exemplo);
- Exige implementação de retentativas por parte de quem envia uma requisição;
- Por padrão, é síncrono, portanto, caso haja degradação do lado que recebe a comunicação, o fluxo todo pode ser interrompido.
Mas, felizmente, há alternativas para todo mundo ficar feliz 😉
 Comunicação assíncrona: utilizando eventos e mensageria
Comunicação assíncrona: utilizando eventos e mensageria
Neste modelo, entra em cena uma estrutura independente das aplicações: os brokers de mensageria.
Esse tipo de middleware oferece estruturas de comunicação e dados que permitem que diferentes serviços conversem entre si de forma assíncrona, segura, replicada e altamente tolerante a falhas.
 Existem diversas soluções comerciais e opensource que provêm deste tipo de estrutura: IBM MQ, Rabbit MQ, Active MQ e, o nosso favorito e sobre o qual vamos falar mais, o Apache Kafka.
Existem diversas soluções comerciais e opensource que provêm deste tipo de estrutura: IBM MQ, Rabbit MQ, Active MQ e, o nosso favorito e sobre o qual vamos falar mais, o Apache Kafka.
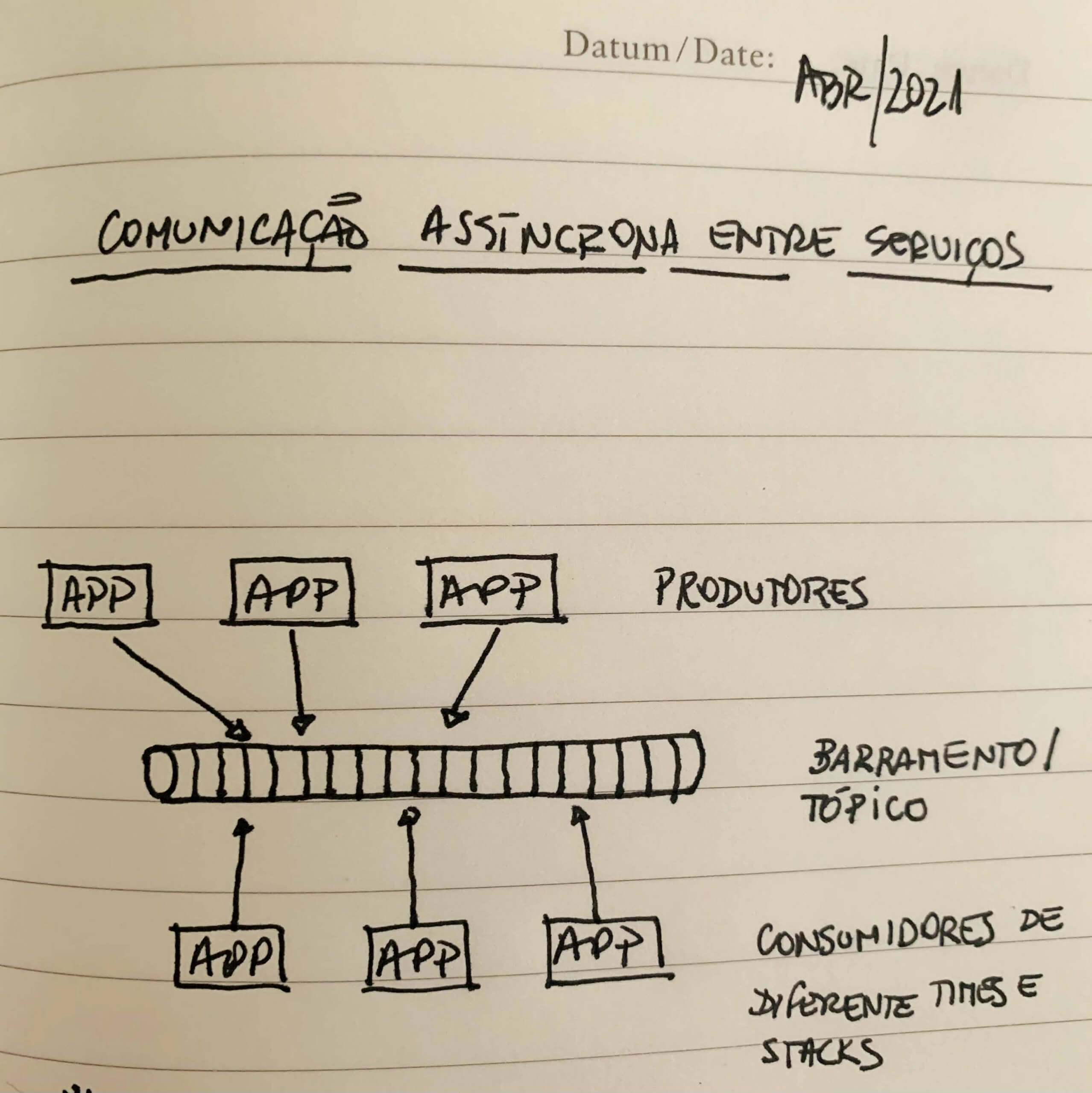
Nesse paradigma de comunicação – e especificamente no Apache Kafka – existem alguns conceitos básicos muito importantes:
- Brokers -> componentes do cluster de mensageria, que permitem a comunicação com os serviços, armazenam, replicam e fornecem toda garantia de integridade dos dados.
- Tópicos -> estruturas de dados que armazenam as mensagens produzidas e consumidas por serviços. Eles são criados de forma a fazerem sentido para a vida real como, por exemplo, tópico para eventos de compras em um e-commerce e novos pedidos em um aplicativo de delivery. Muitos chamam os tópicos de filas, mas isso fica para outro post!
- Produtores -> serviços que produzem mensagens no broker, indicando que um novo evento aconteceu. Seguindo o exemplo usado nos tópicos, o serviço de checkout de um e-commerce pode produzir eventos com mensagens a cada nova compra realizada numa loja on-line.
- Consumidores -> serviços que consomem mensagens no broker, iniciando um novo fluxo de processos de acordo com a sua missão. Um exemplo pode ser um serviço de ordem de produção, que consome eventos produzidos pelo checkout de um e-commerce, dando início ao processo e, ainda pode produzir um novo evento para outros serviços realizarem atividades específicas como produção, logística, fiscal. E, já respondendo a dúvida que acabou de pipocar na sua cabeça, serviços podem sim ser produtores e consumidores de diferentes tópicos!
Mas quais os prós de utilizar o Apache Kafka ou uma solução semelhante?
- Por natureza, o cluster de mensageria é assíncrono, distribuído e escalável, tornando-o tolerante a falhas.
- Permite uma enorme visibilidade do fluxo, devido à forma como se organizam os tópicos e às métricas que são coletadas.
- Diferentes times podem consumir os mesmos eventos para gerar diferentes informações. Por exemplo, times de operações podem consumir eventos de pedidos para medir throughput na plataforma e graficar possíveis gargalos, times de big data podem consumir os mesmos eventos para gerar insights de negócios e, claro, os times de dev consomem os eventos que foram originalmente direcionados a suas aplicações para dar andamento nos fluxos dos processos.
- Pode-se integrar eventos gerados em outras fontes de dados, como bancos relacionais, sensores de IoT etc.
Só que nada é perfeito, não é mesmo?
Então, um dos principais contras desse tipo de arquitetura é justamente a entrada de novos componentes de infraestrutura – como servidores e storage – para atender o cluster de mensageria e, como consequência, o custo do seu projeto pode ter um incremento que precisa ser considerado.
E aí, como está a arquitetura da sua aplicação e qual modelo de comunicação você utiliza?
Leia também: O que é IaC (Infrastructure as Code)?